对于留学生和学术研究人员而言,阅读海量的外文文献是日常学习与科研中不可或缺的一环。然而,在这个过程中,我们经常会遇到一个令人头疼的"拦路虎"——扫描版 PDF 文件。无论是年代久远的经典学术著作、图书馆里复印的参考书章节,还是导师发来的内部讲义,这些资料往往以图片或扫描件的形式存在。
普通的翻译工具对这些"死文本"束手无策,这就凸显了专业 OCR 翻译软件的不可替代性。
本文将深入探讨学术用户在处理扫描件时面临的真实痛点,揭示扫描件翻译中常见的误区,并为您提供一份详尽的选型指南,帮助您找到最适合科研与留学生活的翻译利器。
为什么学术用户离不开专业的 OCR 翻译软件?
在学术研究的语境下,阅读文献不仅仅是获取字面意思,更是对知识的深度挖掘与批判性思考。当留学生或科研人员面对一份数百页的英文扫描版 PDF 时,如果缺乏高效的工具,整个阅读过程将变得极其低效且痛苦。
首先,扫描件的最大特征是"文本不可选"。这意味着你无法像处理常规 Word 文档或原生 PDF 那样,直接复制不认识的单词或段落去查词典。
传统的做法是手动将英文敲入翻译软件,这不仅耗时耗力,还会严重打断阅读的连贯性,导致"心流"状态频频受挫。光学字符识别(OCR)技术的介入,正是为了打破这一物理屏障,它能够智能地将图片中的像素转化为计算机可读取的字符,从而为后续的机器翻译铺平道路。

其次,学术文献的排版通常非常复杂。双栏布局、密集的脚注、穿插其中的数据图表以及复杂的数学公式,都是学术论文的标配。许多基础的翻译工具在处理这些内容时,往往会破坏原有的排版结构,导致翻译出来的文本变成一团乱麻,图表与文字脱节,公式变成乱码。
专业的 OCR 翻译软件必须具备强大的版面分析能力,能够在提取文本的同时,完美还原原始文档的视觉结构。
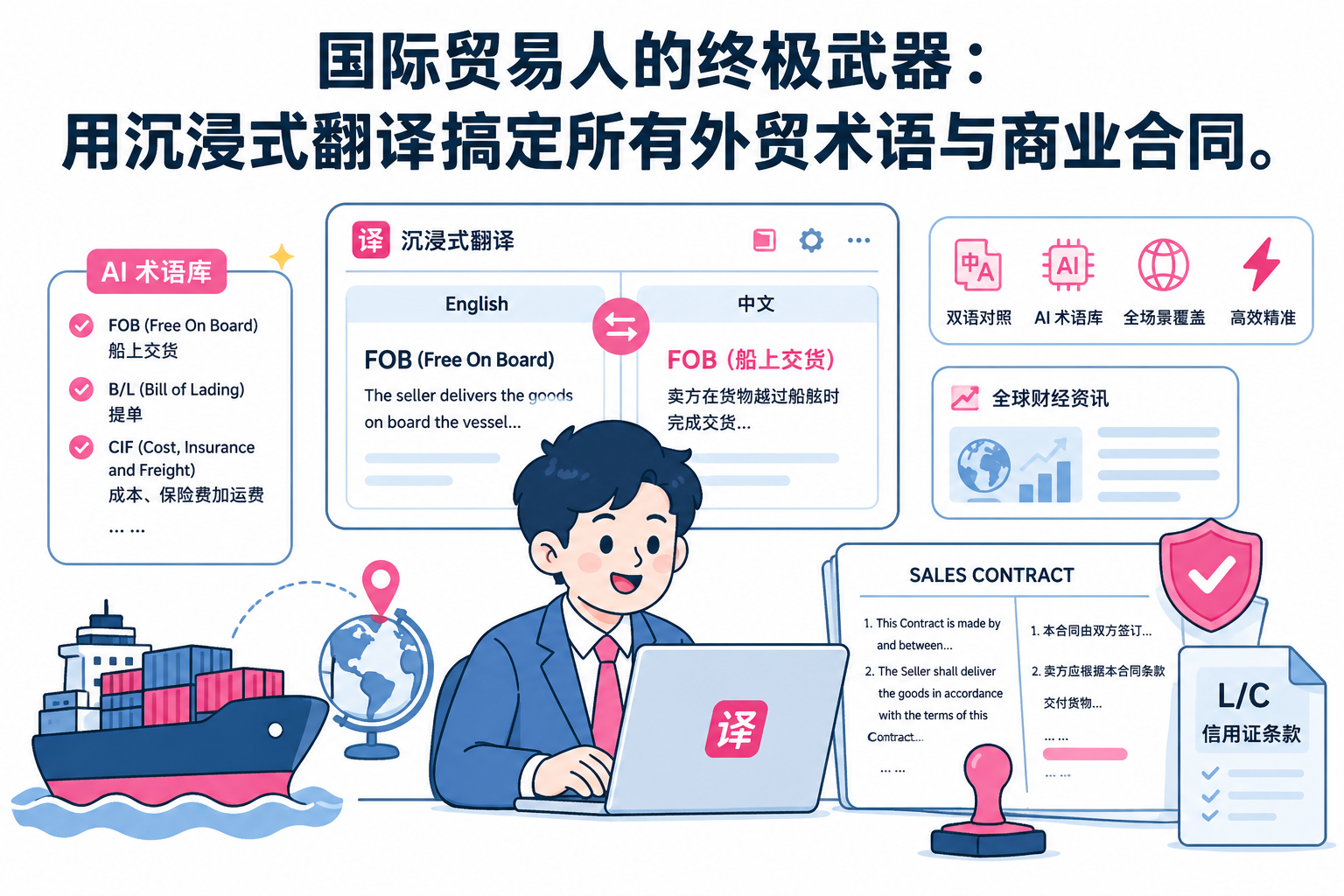
最后,学术翻译对专业术语的准确性要求极高。不同于日常交流,科研领域的词汇往往具有特定的学术内涵。如果翻译软件仅仅依赖通用的语料库进行直译,很容易产生令人啼笑皆非的错误,甚至误导研究方向。因此,一款优秀的扫描件翻译工具,必须能够接入先进的 AI 大语言模型,结合上下文语境提供精准的专业翻译。

扫描件翻译的常见误区与潜在风险
尽管 OCR 翻译软件极大地提升了我们处理文献的效率,但在实际使用中,许多留学生和研究人员容易陷入一些误区,忽视了潜在的风险。
一个常见的误区是"过度依赖工具而放弃原文核对"。虽然现代 AI 驱动的 OCR 技术准确率已经非常高,但在处理低分辨率扫描件、褪色文档或特殊字体时,仍然可能出现识别错误。例如,在医学或化学文献中,一个字母的误识(如将"l"识别为"1",或漏掉微小的下标)可能会导致完全不同的实验结论。如果用户盲目相信翻译结果,而不去对照原文核对关键数据和公式,将给学术研究带来致命的隐患。
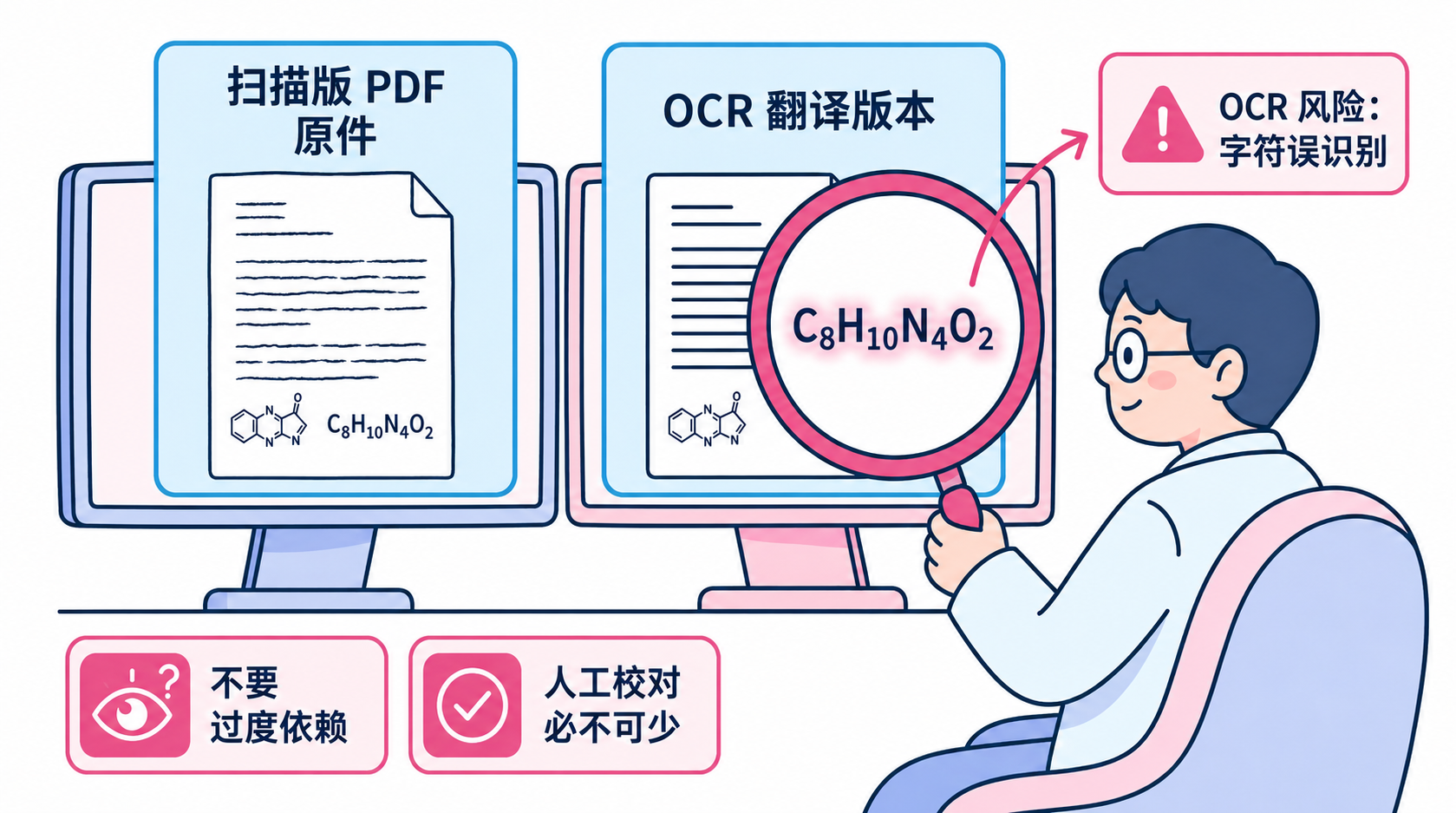
另一个误区是认为"所有 OCR 工具都能完美处理手写体"。实际上,尽管印刷体文本的识别技术已经非常成熟,但手写体的 OCR 仍然是业界公认的难题。导师在讲义边缘的潦草批注、档案馆里借阅的历史手稿,往往会让大多数常规 OCR 翻译软件败下阵来。
对于这类极具挑战性的扫描件,用户应当有合理的预期,并在必要时结合人工转录,而不是完全指望软件一步到位。
留学生的高频使用场景:不止于学术论文
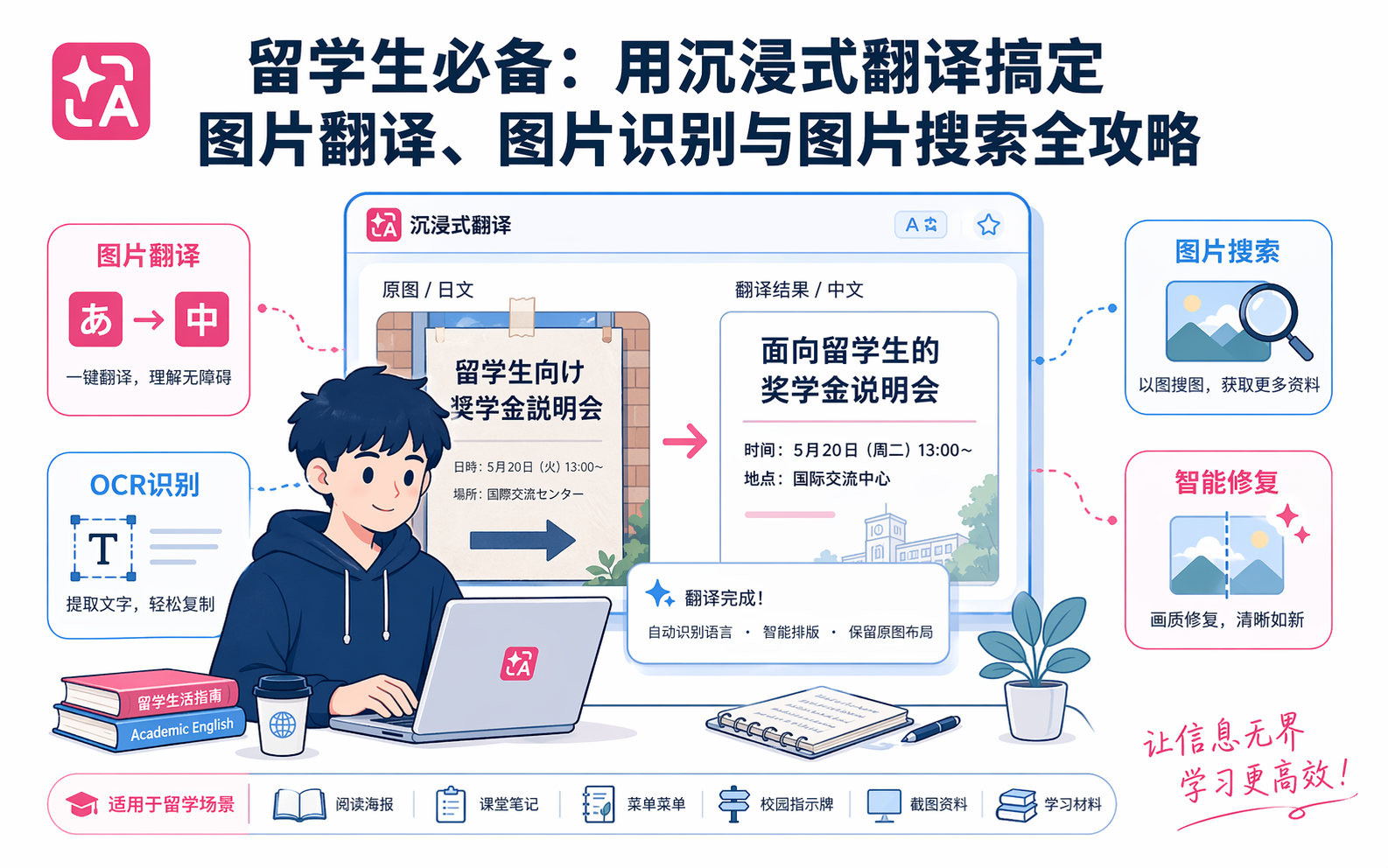
当我们谈论 OCR 翻译软件时,第一反应往往是"看论文"。然而,对于身处异国他乡的留学生来说,扫描件翻译的需求远比想象中更加广泛和高频,它渗透到了学习与生活的方方面面。
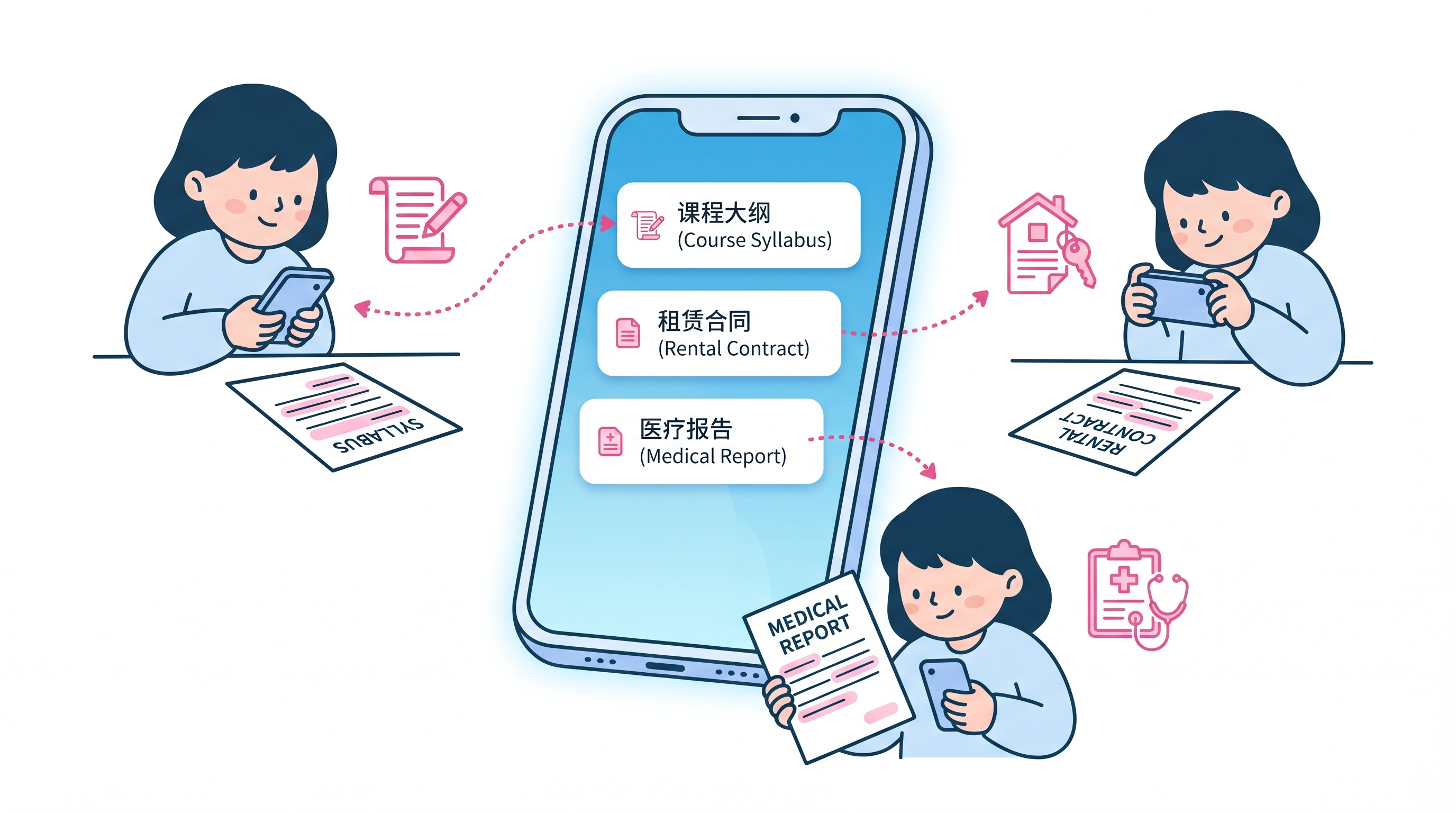
在学业方面,除了正式发表的期刊文章,留学生还需要处理大量非标准格式的学术材料。例如,开学初教授发放的纸质版课程大纲(Syllabus),上面详细列出了整个学期的阅读书目、评分标准和 Deadline;或者是课堂上教授随手写下的板书照片、实验室里的操作规程扫描件。这些资料往往没有电子版,留学生必须借助 OCR 翻译软件快速将其转化为母语,以确保不遗漏任何关键的学术要求。
在生活方面,OCR 翻译软件同样是留学生不可或缺的生存工具。初到海外,租房是头等大事。长达十几页的英文租房合同扫描件,里面充满了晦涩的法律术语和免责条款。如果不能准确理解其中的每一项规定,极易在日后产生纠纷。
此外,医院开具的纸质体检报告、银行邮寄的纸质账单、甚至是不小心收到的交通罚单,这些往往都是以图片或扫描件的形式存在。通过拍照并使用 OCR 翻译,留学生能够迅速掌握关键信息,从容应对海外生活中的各种挑战。
挑选 OCR 翻译软件的 4 大核心标准
面对市面上琳琅满目的 PDF 翻译工具,学术用户应该如何挑选出最适合自己的一款呢?我们总结了以下四个核心评估标准:
第一,卓越的版式还原能力。这是衡量一款 PDF 翻译软件是否专业的分水岭。优秀的工具不仅能准确翻译文本,还能智能识别双栏排版、表格结构、图片位置以及页眉页脚,并在翻译后的文档中保留这些内容。这样,你在阅读译文时,不会遗漏关键信息。
第二,强大的多引擎 AI 翻译支持。学术领域的细分方向极其繁杂,没有哪一个翻译引擎能够包打天下。理想的翻译软件应该内置或支持接入多种顶级 AI 模型(如 GPT- 5、Claude、DeepL 等)。这样,用户可以根据文献的性质灵活切换:对于标准化的法律合同,使用 DeepL 获取地道表达;对于逻辑复杂的长篇综述,则调用 GPT-5 / Claude 等强大的上下文理解能力。
第三,双语对照阅读模式。正如前文所述,学术研究绝不能完全脱离原文。一款好用的翻译软件必须提供便捷的双语对照功能(例如段落级别的中英对照,或左右分栏显示)。这不仅有助于用户随时核对存疑的专业术语,更是留学生在阅读中潜移默化提升专业英语水平的绝佳途径。
第四,高效的本地化处理与隐私保护。学术文献往往涉及未公开的研究数据或敏感的商业信息。因此,软件在处理文档时的数据安全性至关重要。同时,对于动辄几十兆、上百页的超大 PDF 扫描件,软件的处理速度和稳定性也是考验其技术实力的重要指标。
沉浸式翻译:为复杂 PDF 扫描件而生的翻译利器
在众多评测与用户反馈中,沉浸式翻译(Immersive Translate)凭借其针对复杂文档的深度优化,脱颖而出,成为许多留学生和科研党的首选工具。
针对学术用户最头疼的排版问题,沉浸式翻译的 PDF Pro 版本展现出了惊人的解析能力。它能够精准识别双栏和三栏等复杂布局,确保翻译后的文本不会出现跨栏断句的尴尬。更令人惊喜的是,它对学术文献中常见的表格和数学公式有着极高的兼容性。即使是嵌套复杂的表格,沉浸式翻译也能在不改变表格结构的前提下进行对照翻译;而对于那些让普通 OCR 软件直接宕机的科学公式,它也能借助先进的 AI 技术进行精确识别与保留,完全不影响科研人员的阅读体验。
在翻译质量方面,沉浸式翻译内置了包括 OpenAI、DeepL、Gemini 在内的 20 多种顶级 AI 翻译引擎。用户可以根据自己的专业领域和文献类型,自由选择最合适的模型,从而获得远超传统机翻的精准度和流畅度。
此外,沉浸式翻译标志性的"双语对照"功能在 PDF 翻译中也得到了完美继承。它将译文自然地嵌入到原文下方,保留了轻松易读的格式。这种沉浸式的双语阅读体验,不仅极大地降低了阅读外文长卷的认知负担,也让随时核对原文变得轻而易举。

结语:让工具成为学术研究的加速器
在信息爆炸的时代,学术竞争往往也是效率的竞争。面对浩如烟海的外文文献和难以处理的扫描版 PDF,我们不应将宝贵的时间和精力消耗在低效的查词和死磕格式上。
一款优秀的 OCR 翻译软件,不仅是语言转换的桥梁,更是知识获取的加速器。它帮助留学生打破语言与物理介质的双重壁垒,让我们能够以更加从容、高效的姿态,沉浸在学术研究的广阔天地中。选择合适的工具,掌握科学的阅读方法,相信您一定能在留学与科研的道路上走得行远致稳。